JEnExtrA (Jena Entity Extraction Application)
Software for automated extraction, disambiguation, and specification of named entities in texts

Social scientists contemporarily explore sophisticated text-mining tools for big data analysis. One class of tools attracting considerable attention is named entity recognizers, which provide the ability to detect social actors and classify them as persons and organizations. However, it remains a technical challenge to automatically disambiguate (who is referred to in a text?) and specify (which demographic characteristics are present?) social actors. JEnExtrA is a reliable and accurate software architecture for social scientists who are interested in automatically detecting, disambiguating, and demographically specifying social actors in big data. The software architecture utilizes the online encyclopedia Wikipedia.
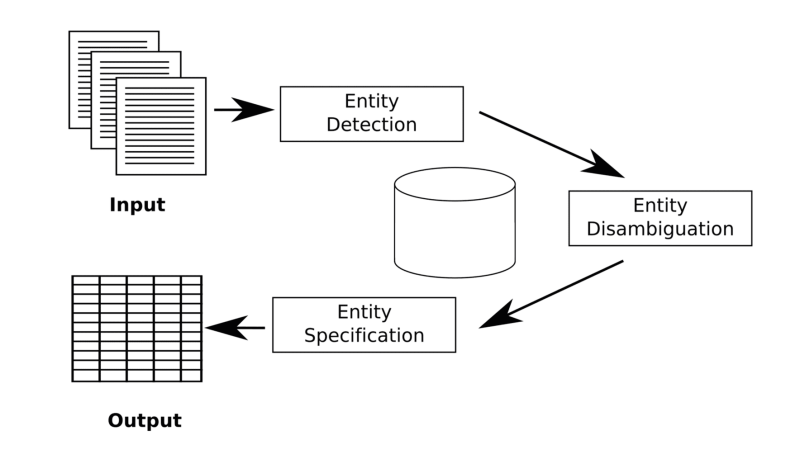
JenExtrA
Image: Poschmann / GoldensteinFor a more detailed description of the software application please refer to our article in which you also find an demonstration example:
Poschmann, Philipp & Goldenstein, Jan (2019): Disambiguating and Specifying Social Actors in Big Data: Using Wikipedia as a Data Source for Demographic InformationExternal link, Sociological Methods & Research 51(2), 887-925..
If you apply the software application to your own research, please cite our article.
The software runs on Windows, Mac, and Linux. It requires at least 4 GB RAM and 600 MB (software only) hard drive space and approx. 30 GB for the data sets (for local mode).
1. All users of JEnExtrA must sign an use agreement in order to receive a copy (user agreementpdf, 104 kb · de).
2. Please send the use agreement to jencora@uni-jena.de (subject: "JEnExtrA use agreement").
3. In the following days, you will receive a download link, which is valid for 20 days.