JenParA (Jena Parser Application)
Software for automated linguistic content analysis using grammatical parsing and topic modeling

Social scientists recently started discussing the utilization of text-mining tools as being fruitful for content analysis. To enable social scientists who are not familiar with computer science and software development to use sophisticated text-mining tools, we aim at providing a fully developed and reliable software application that enables grammatical parsing and the extraction of semantic triplets (i.e., subject-verb-object relations). For grammatical parsing we draw on state-of-the-art software, namely Stanford’s CoreNLP.
Notably, our software’s output, which depicts semantic triplets, is suitable for researchers to add topic modeling results from each software package that they like to use. We decided to include our own topic-modeling scripts based on the “lda” Python package to make topic modeling broadly accessible for social scientists. We thus provide the software scripts needed for executing topic modeling and validating its results.
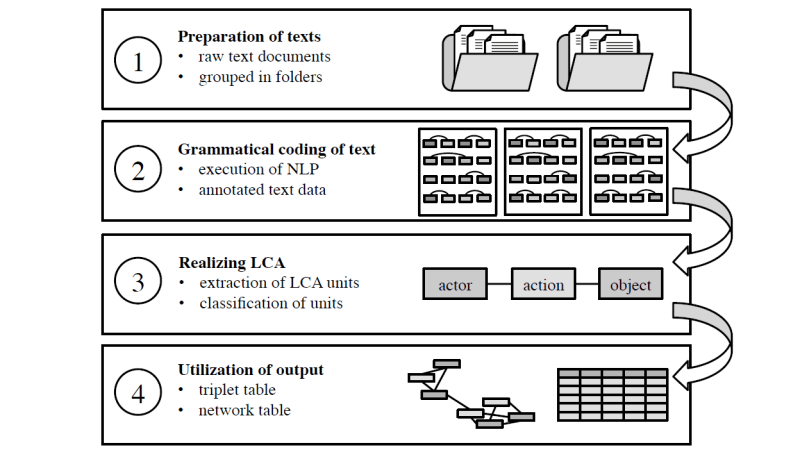
JenParA Framework
Image: Goldenstein / PoschmannFor a more detailed description of the software application please refer to our article in which you also find a demonstration example:
Goldenstein, Jan & Poschmann, Philipp (2019): Analyzing Meaning in Big Data: Performing a Map Analysis Using Grammatical Parsing and Topic ModelingExternal link, Sociological Methodology 49(1): 83-131.
If you apply the software application to your own research, please cite our article.
The article was published in the context of a symposium. If you are interested, see also our rejoinder in this debate:
Goldenstein, Jan & Poschmann, Philipp (2019): Rejoinder: A Quest for Transparent and Reproducible Text-Mining Methodologies in Computational Social Science, Sociological Methodology 49(1): 144-151.
The software runs on Windows, Mac, and Linux. It requires at least 5 GB RAM and 1 GB free hard drive space.
To run the software, you need at least Java 8. All other required libraries are included in the library folder of the tool. In the README file, you can find a list of the used open-source packages.
1. All users of JenParA must sign an use agreement in order to receive a copy (use agreementpdf, 41 kb · de).
2. Please send the use agreement to jencora@uni-jena.de (subject: "JenParA use agreement").
3. In the following days, you will receive a download link, which is valid for 20 days.